前言 共享的可变变量 时,会产生不确定的结果,所以要编写线程安全的代码,其本质上是对这些可变的共享变量的访问操作进行管理。导致这种不确定结果的原因就是可见性、有序性和原子性问题,Java 为解决可见性和有序性问题引入了 Java 内存模型 (JMM) ,使用互斥方案(其核心实现技术是锁)来解决原子性问题,这篇先来看看解决可见性、有序性问题的 Java 内存模型(JMM)。什么是 Java 内存模型 The Java memory model describes how threads in the Java programming language interact through memory. Together with the description of single-threaded execution of code, the memory model provides
the semantics of the Java programming language.
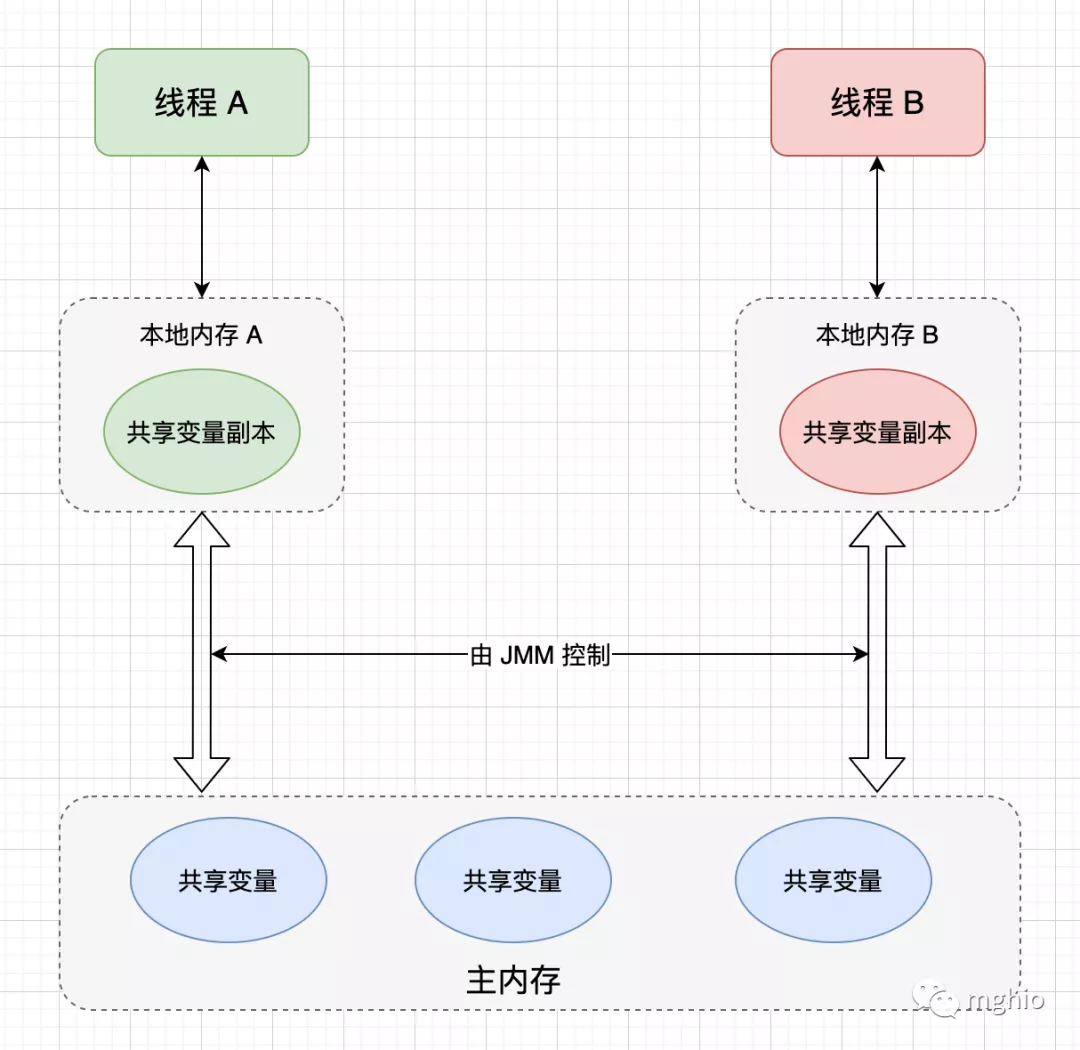
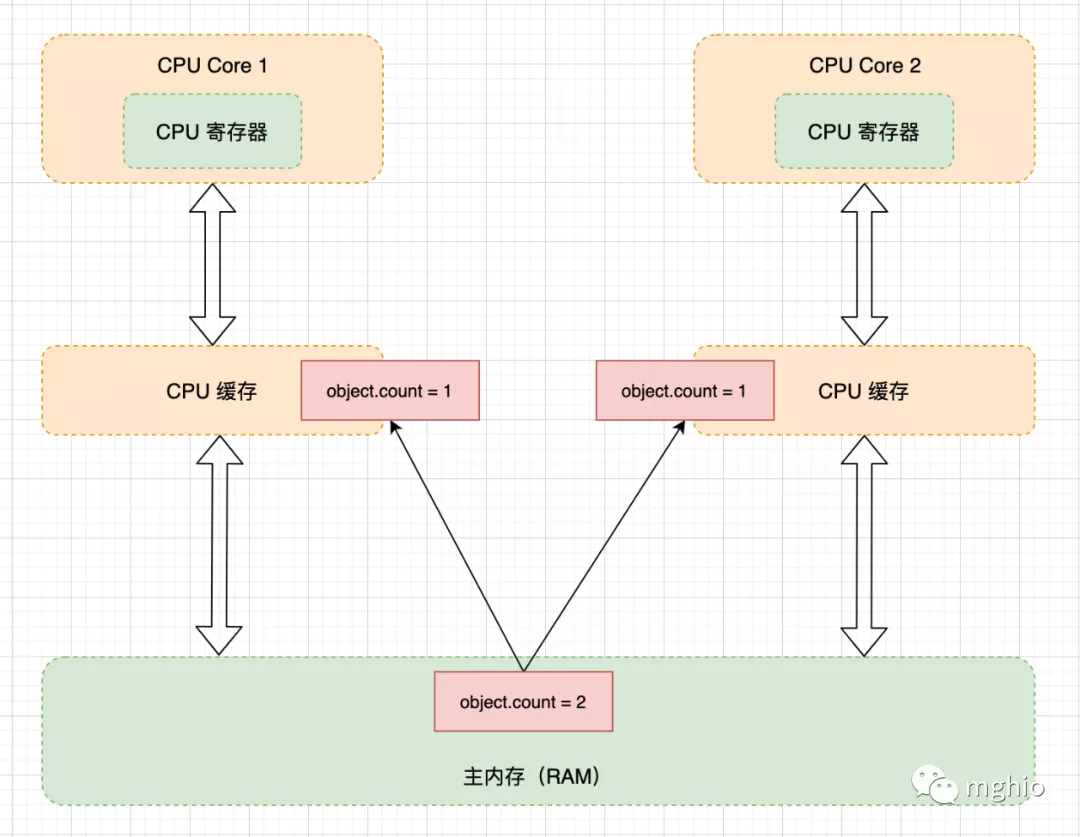
共享的内存模型 ,在共享的内存模型里,多线程之间共享程序的公共状态,通过读-写内存的方式来进行隐式通讯。线程 A 把在本地内存更新后的共享变量副本的值,刷新到主内存中。 线程 B 在使用到该共享变量时,到主内存中去读取线程 A 更新后的共享变量的值,并更新线程 B 本地内存的值。 为什么需要 Java 内存模型 缓存 。/**
* @author mghio
* @since 2021-08-22
*/
public class DoubleCheckedInstance {
private static DoubleCheckedInstance instance;
public static DoubleCheckedInstance getInstance() {
if (instance == null) {
synchronized (DoubleCheckedInstance.class) {
if (instance == null) {
instance = new DoubleCheckedInstance();
}
}
}
return instance;
}
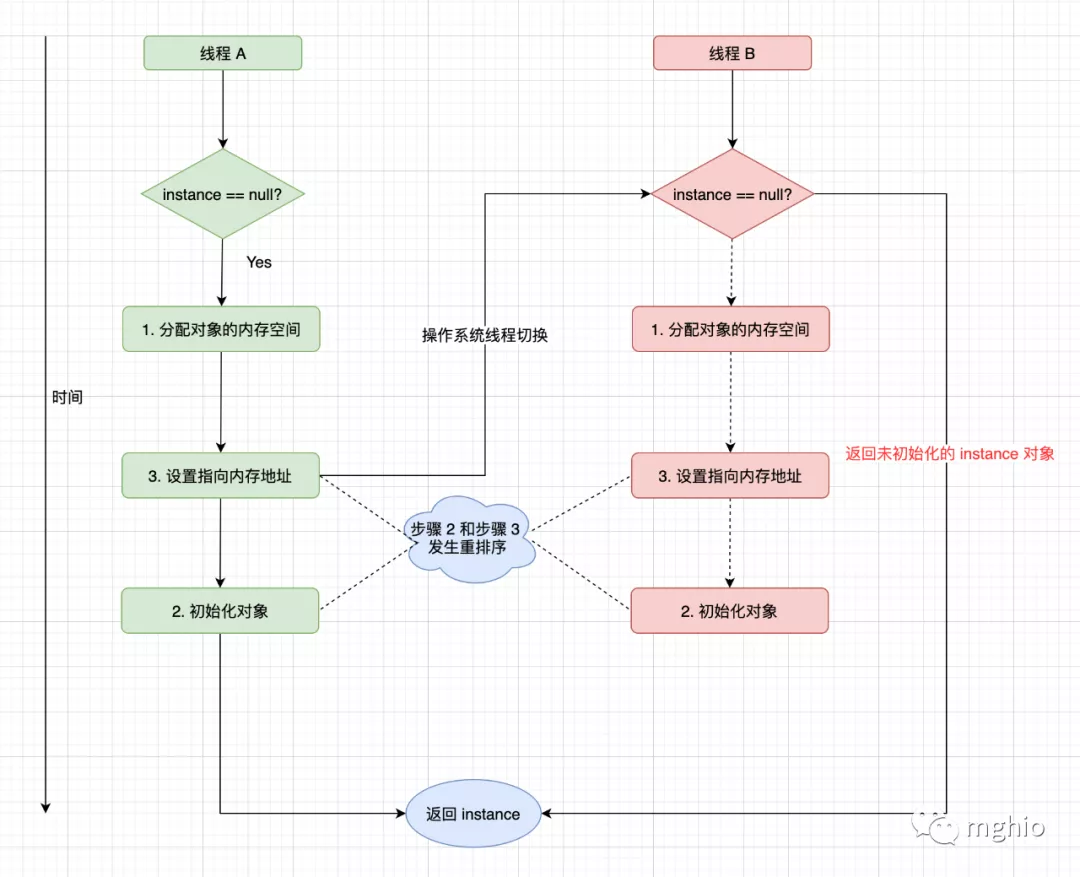
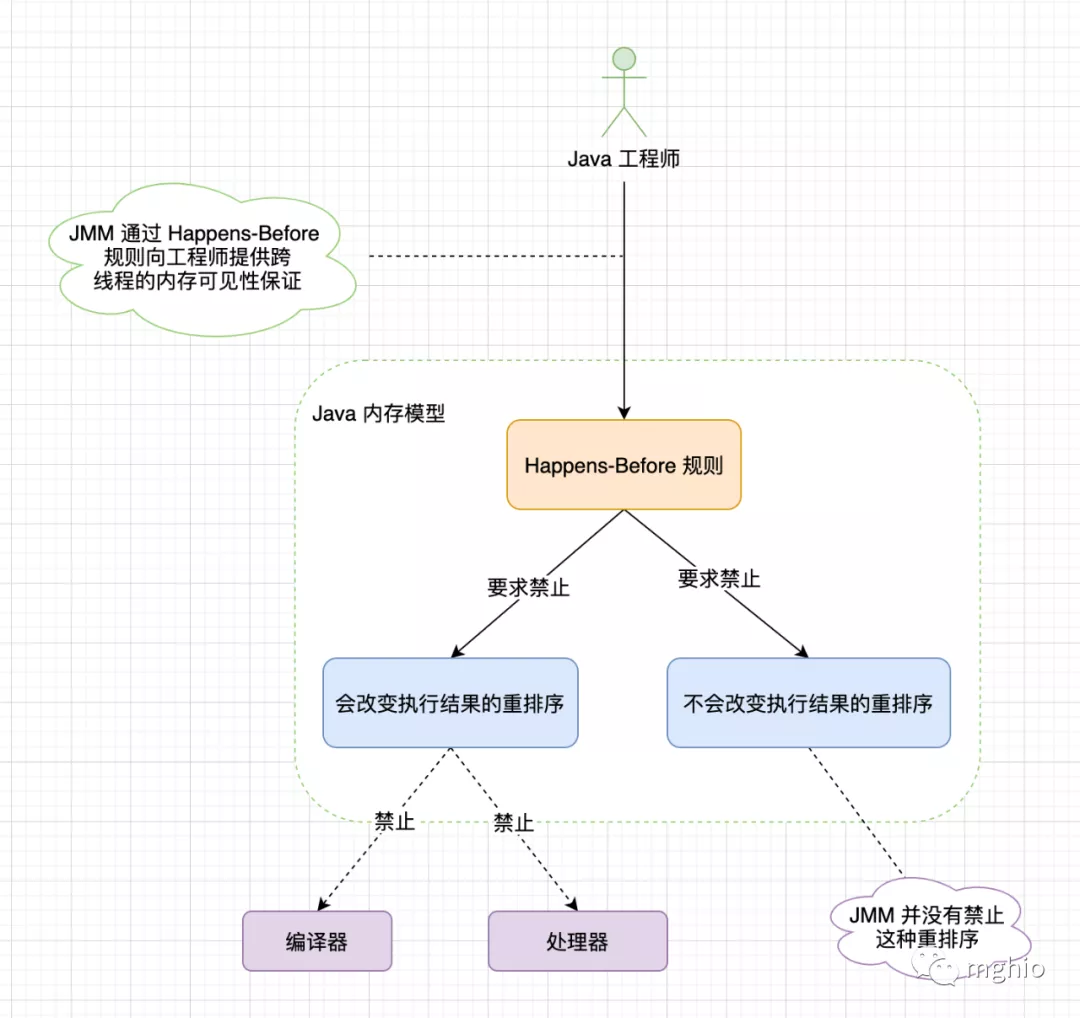
}分配对象的内存空间 初始化对象 设置 instance 指向刚刚已经分配的内存地址 顺序一致性内存模型 一个线程中的所有操作必须按照程序的顺序来执行 所有的线程都只能看到一个单一的执行操作顺序,不管程序是否同步 Happens-Before 规则 程序顺序规则 一个线程中的每个操作,Happens-Before 该线程中的任意后续操作监视器锁规则 对一个锁的解锁操作,Happens-Before 于后面对这个锁的加锁操作volatile 规则 对一个 volatile 类型的变量的写操作,Happens-Before 与任意后面对这个 volatile 变量的读操作传递性规则 如果操作 A Happens-Before 于操作 B,并且操作 B Happens-Before 于操作 C,则操作 A Happens-Before 于操作 Cstart() 规则 如果一个线程 A 执行操作 threadB.start() 启动线程 B,那么线程 A 的 start() 操作 Happens-Before 于线程 B 的任意操作join() 规则 如果线程 A 执行操作 threadB.join() 并成功返回,那么线程 B 中的任意操作 Happens-Before 于线程 A 从 threadB.join() 操作成功返回总结 

 QQ好友和群
QQ好友和群 QQ空间
QQ空间