
[jQuery] MySQL面试:left join我要怎优化?
![]() 开发技术
发布于:2021-12-21 22:15
|
阅读数:648
|
评论:0
开发技术
发布于:2021-12-21 22:15
|
阅读数:648
|
评论:0
免责声明:
1. 本站所有资源来自网络搜集或用户上传,仅作为参考不担保其准确性! 2. 本站内容仅供学习和交流使用,版权归原作者所有!© 查看更多 3. 如有内容侵害到您,请联系我们尽快删除,邮箱:kf@codeae.com | ||


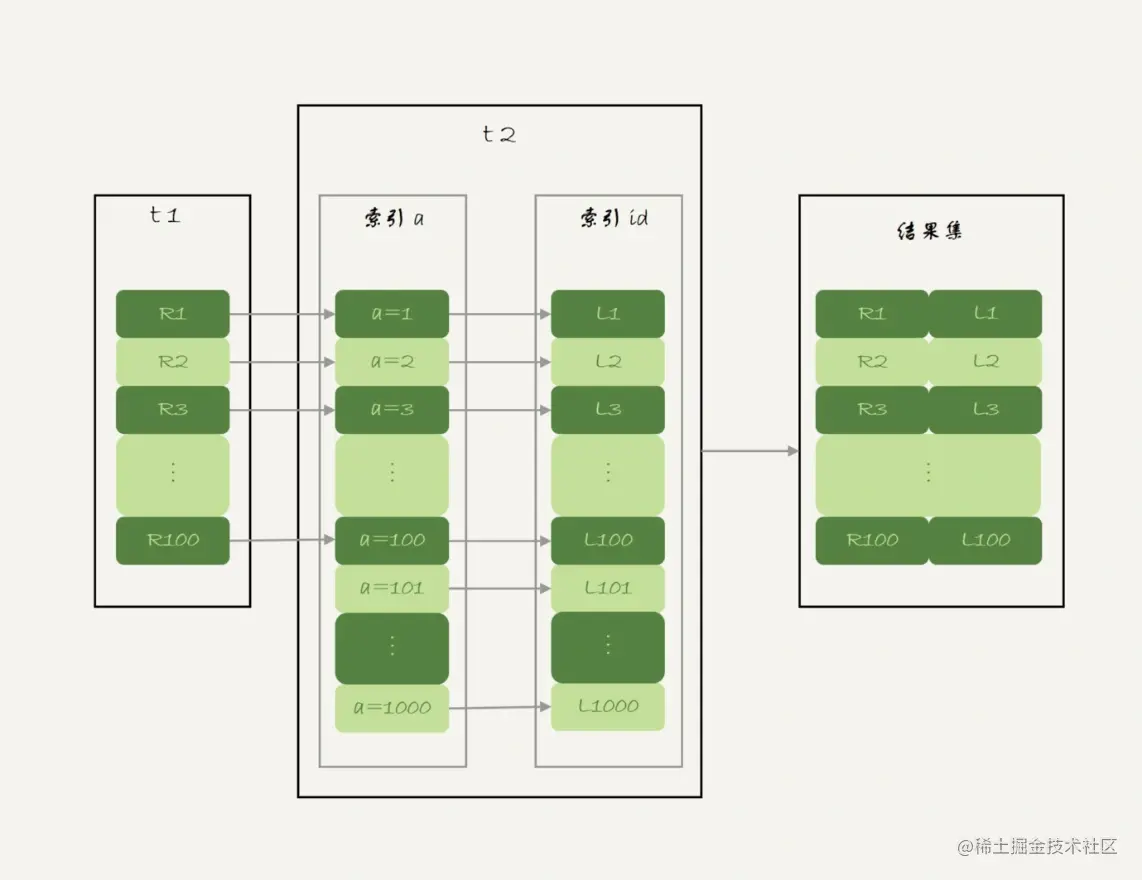
 结果就是两个表都要全表扫描,这里我们看到,Extra显示的是(Using where; Using join buffer (Block Nested Loop))
结果就是两个表都要全表扫描,这里我们看到,Extra显示的是(Using where; Using join buffer (Block Nested Loop))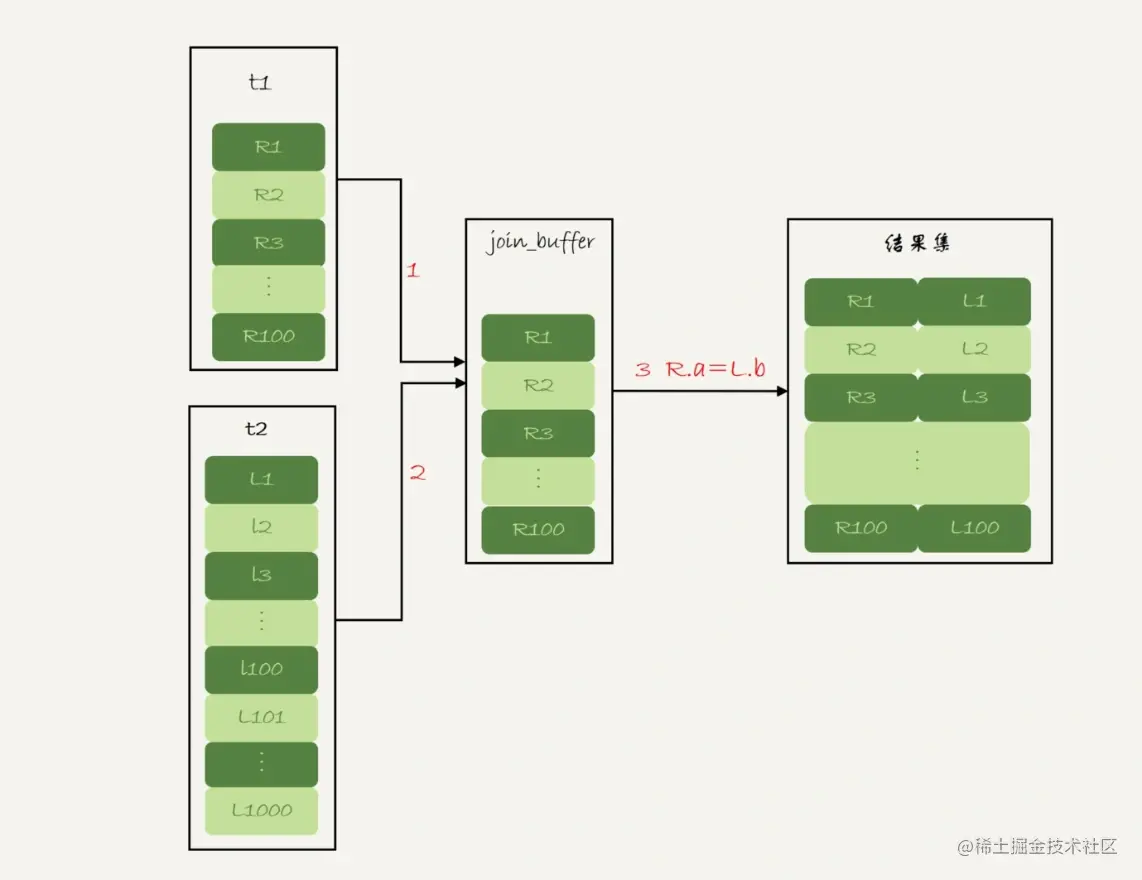
 QQ好友和群
QQ好友和群 QQ空间
QQ空间
相关帖子
-
MySQL数据库触发器从小白到精通
小蚂蚁 阅读 542 0 赞
-
一篇带给你MySQL索引知识详解
飞奔的炮台 阅读 547 0 赞
-
MySQL视图和索引专篇精讲
Shun 阅读 644 0 赞
-
阿里面试MySQL死锁问题的处理
小蚂蚁 阅读 449 0 赞
-
mysql中drop、truncate与delete的区别详析
三叶草 阅读 699 0 赞
-
docx文件怎样打开进行修改
PHP小丑 阅读 209 0 赞
-
电力猫怎么配对 TP-Link电力猫和扩展器配对教程
PHP小丑 阅读 434 0 赞
-
电力猫配对 TP-Link电力猫和扩展器配对教程
CodeAE 阅读 1237 0 赞
-
js数组之间如何进行连接
CodeAE 阅读 237 0 赞
-
怎么在JavaScript中加注释
CodeAE 阅读 251 0 赞

发布文档 3257
热门推荐
-
关于GBK与UTF-8互转乱码问题解读
CodeAE 2025-03-09
-
EasyBCD系统引导修复工具 V2.4.0 中文版
CodeAE 2024-12-14
-
图吧工具箱2024.9绿色版
CodeAE 2024-12-12
-
Win10右键管理提示“该文件没有与之关联的程序来执行此操作”怎么办
CodeAE 2024-12-08
-
如何白嫖一张永不过期的SSL证书
CodeAE 2024-11-17
-
自己动手写一个挪车通知工具
CodeAE 2024-11-10
-
如何利用html+js写一个大小写字母互转工具
CodeAE 2024-10-20
-
Discuz教程-帖子里有多个MP4媒体,默认只播放一个
CodeAE 2024-10-13
-
Discuz教程-禁止复制及使用f12开发者模式
CodeAE 2024-10-13
-
C/C++实现植物大战僵尸
CodeAE 2024-10-05
-
B站视频下载工具 Bilidown 1.2.0
CodeAE 2024-10-03
-
2024显卡天梯图一览表
CodeAE 2024-09-01
-
win10怎么查看电脑配置显卡 电脑查看显卡配置方法
CodeAE 2024-08-25
-
Word文档中的doc和docx格式有什么区别?
CodeAE 2024-07-21
-
禁止win10更新的方法
CodeAE 2024-06-02
-
查看Window激活状态的方法
CodeAE 2024-05-26
-
利用宝塔面板实现夸克网盘自动签到获取永久容量
CodeAE 2024-05-01
-
阿里云服务器CentOS系统注释磁盘命令
CodeAE 2024-03-17