[Oracle]
线程共享和协作(二)(1),升职加薪必看
 数据库
发布于:2021-12-26 14:18
|
阅读数:340
|
评论:0
数据库
发布于:2021-12-26 14:18
|
阅读数:340
|
评论:0
|
|
try {
Thread.sleep(1000); // 睡一秒,给线程3时间做ABA操作
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("AtomicStampedReference原子操作:" + a2.compareAndSet(10, 11, stamp, stamp + 1));
}
}
}
[]( )Volatile
[]( )作用
Volatile可以看做是一个轻量级的synchronized,它可以在多线程并发的情况下保证变量的“可见性”,
什么是可见性?
就是在一个线程的工作内存中修改了该变量的值,该变量的值立即能回显到主内存中,从而保证所有的线程看到这个变量的值是一致的,其二 volatile 禁止了指令重排,所以在处理同步问题上它大显作用,而且它的开销比synchronized小、使用成本更低。
虽然 volatile 变量具有可见性和禁止指令重排序,但是并不能说 volatile 变量能确保并发安全。
举个栗子:在写单例模式中,除了用静态内部类外,还有一种写法也非常受欢迎,就是Volatile+DCL:
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
这样单例不管在哪个线程中创建的,所有线程都是共享这个单例的。
虽说这个Volatile关键字可以解决多线程环境下的同步问题,不过这也是相对的,因为它不具有操作的原子性,也就是它不适合在对该变量的写操作依赖于变量本身自己。举个最简单的栗子:在进行计数操作时count++,实际是count=count+1;,count最终的值依赖于它本身的值。所以使用volatile修饰的变量在进行这么一系列的操作的时候,就有并发的问题 .
volatile只能确保操作的是同一块内存,并不能保证操作的原子性。所以volatile一般用于声明简单类型变量,使得这些变量具有原子性,即一些简单的赋值与返回操作将被确保不中断。但是当该变量的值由自身的上一个决定时,volatile的作用就将失效,这是由volatile关键字的性质所决定的。
所以在volatile时一定要谨慎,千万不要以为用volatile修饰后该变量的所有操作都是原子操作,不再需要synchronized关键字了。
[]( )用法
因为volatile不具有操作的原子性,所以如果用volatile修饰的变量在进行依赖于它自身的操作时,就有并发问题,如:count,像下面这样写在并发环境中是达不到任何效果的:
public class Counter {
private volatile int count;
public int getCount(){
return count;
}
public void increment(){
count++;
}
}
而要想count能在并发环境中保持数据的一致性,则可以在increment()中加synchronized同步锁修饰,改进后的为:
public class Counter {
private volatile/无 int count;
public int getCount(){
return count;
}
public synchronized void increment(){
count++;
}
}
[]( )内部实现
汇编指令实现
[]( )Synchronized
[]( )作用
synchronized关键字是Java利用锁的机制自动实现的,一般有同步方法和同步代码块两种使用方式。Java中所有的对象都自动含有单一的锁(也称为监视器),当在对象上调用其任意的synchronized方法时,此对象被加锁(一个任务可以多次获得对象的锁,计数会递增),同时在线程从该方法返回之前,该对象内其他所有要调用类中被标记为synchronized的方法的线程都会被阻塞。当然针对每个类也有一个锁(作为类的Class对象的一部分),所以你懂的.。
正因为它基于这种阻塞的策略,所以它的性能不太好,但是由于操作上的优势,只需要简单的声明一下即可,而且被它声明的代码块也是具有操作的原子性。
最后需要注意的是synchronized是同步机制中最安全的一种方式,其他的任何方式都是有风险的,当然付出的代价也是最大的。
[]( )用法
public synchronized void increment(){
count++;
}
public void increment(){
synchronized (Counte.class){
count++;
}
}
[]( )内部实现
[synchronized 关键字原理]( )
[]( )ThreadLocal
[]( )作用
而ThreadLocal的设计,并不是解决资源共享的问题,而是用来提供线程内的局部变量,这样每个线程都自己管理自己的局部变量,别的线程操作的数据不会对我产生影响,互不影响,所以不存在解决资源共享这么一说,如果是解决资源共享,那么其它线程操作的结果必然我需要获取到,而ThreadLocal则是自己管理自己的,相当于封装在Thread内部了,供线程自己管理,这样做其实就是以空间换时间的方式(与synchronized相反),以耗费内存为代价,单大大减少了线程同步(如synchronized)所带来性能消耗以及减少了线程并发控制的复杂度。
[]( )用法
ThreadLocal实例通常来说都是private static类型的,用于关联线程和线程的上下文
一般使用ThreadLocal,官方建议我们定义为private static ,至于为什么要定义成静态的,这和内存泄露有关,后面再讨论。
它有三个暴露的方法,set、get、remove。
public class TestThreadLocal {
private static final ThreadLocal<Integer> value = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
new Thread(new MyThread(i)).start();
}
}
static class MyThread implements Runnable {
private int index;
public MyThread(int index) {
this.index = index;
}
public void run() {
System.out.println("线程" + index + "的初始value:" + value.get());
for (int i = 0; i < 10; i++) {
value.set(value.get() + i);
}
System.out.println("线程" + index + "的累加value:" + value.get());
}
}
}
运行结果如下,这些ThreadLocal变量属于线程内部管理的,互不影响:
线程0的初始value:0
线程3的初始value:0
线程2的初始value:0
线程2的累加value:45
线程1的初始value:0
线程3的累加value:45
线程0的累加value:45
线程1的累加value:45
线程4的初始value:0
线程4的累加value:45
对于get方法,在ThreadLocal没有set值得情况下,默认返回null,所有如果要有一个初始值我们可以重写initialValue()方法,在没有set值得情况下调用get则返回初始值。
[]( )内部实现
ThreadLocal内部有一个静态类ThreadLocalMap,使用到ThreadLocal的线程会与ThreadLocalMap绑定,维护着这个Map对象,而这个ThreadLocalMap的作用是映射当前ThreadLocal对应的值,它key为当前ThreadLocal的弱引用:WeakReference
[]( )内存泄露问题
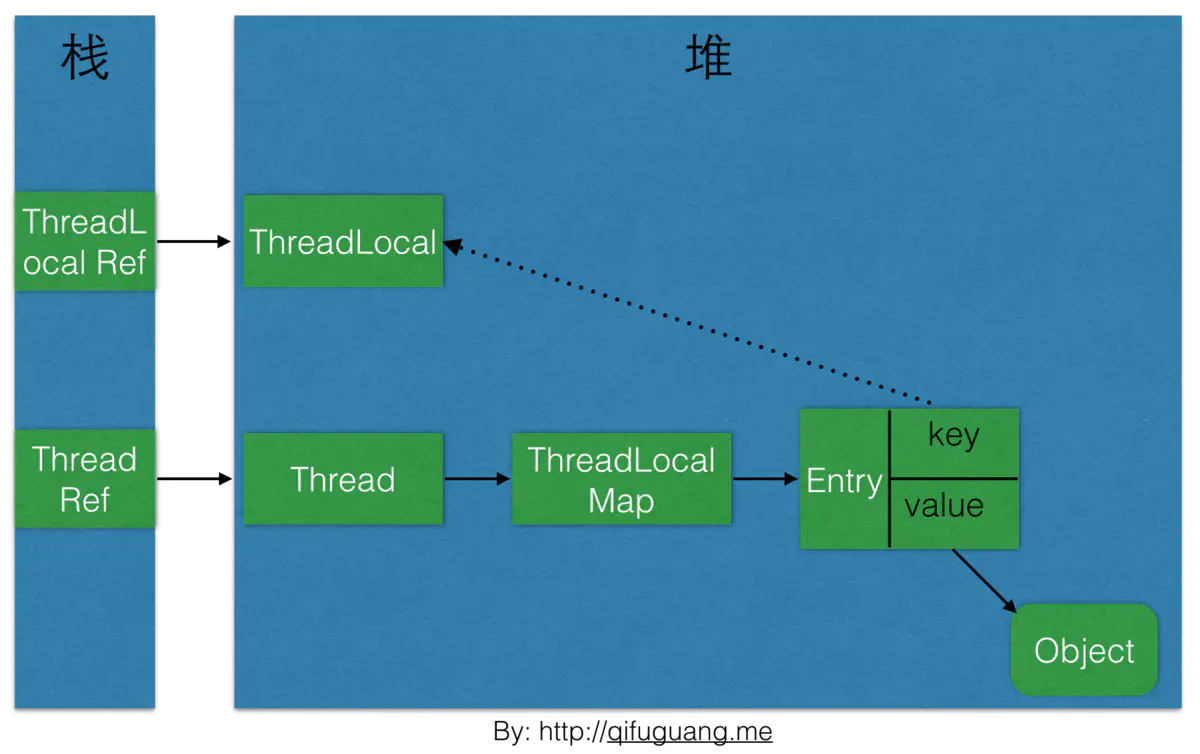
对于ThreadLocal,一直涉及到内存的泄露问题,即当该线程不需要再操作某个ThreadLocal内的值时,应该手动的remove掉,为什么呢?我们来看看ThreadLocal与Thread的联系图:
此图来自网络:
其中虚线表示弱引用,从该图可以看出,一个Thread维持着一个ThreadLocalMap对象,而该Map对象的key又由提供该value的ThreadLocal对象弱引用提供,所以这就有这种情况:
如果ThreadLocal不设为static的,由于Thread的生命周期不可预知,这就导致了当系统gc时将会回收它,而ThreadLocal对象被回收了,此时它对应key必定为null,这就导致了该key对应得value拿不出来了,而value之前被Thread所引用,所以就存在key为null、value存在强引用导致这个Entry回收不了,从而导致内存泄露。
所以避免内存泄露的方法,是对于ThreadLocal要设为static静态的,
这样的话ThreadLocal的生命周期就更长,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露。除了这个,还必须在线程不使用它的值是手动remove掉该ThreadLocal的值,这样Entry就能够在系统gc的时候正常回收,而关于ThreadLocalMap的回收,会在当前Thread销毁之后进行回收。
但需要注意的是,虽然ThreadLocal和Synchonized都用于解决多线程并发访问,ThreadLocal与synchronized还是有本质的区别。synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。即Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。所以ThreadLocal并不能代替synchronized,Synchronized的功能范围更广(同步机制)。
[]( )InheritableThreadLocal
ThreadLocal类固然很好,但是子线程并不能取到父线程的ThreadLocal类的变量,InheritableThreadLocal类就是解决这个问题的。
/**
*TODO 验证线程变量间的隔离性
*/
public class Test3 {
public static void main(String[] args) {
try {
for (int i = 0; i < 10; i++) {
System.out.println(" 在Main线程中取值=" + Tools.tl.get());
Thread.sleep(100);
}
Thread.sleep(5000);
ThreadA a = new ThreadA();
a.start();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/*static public class Tools {
public static ThreadLocalExt tl = new ThreadLocalExt();
}
static public class ThreadLocalExt extends ThreadLocal {
@Override
protected Object initialValue() {
return new Date().getTime();
}
}*/
static public class Tools {
public static InheritableThreadLocalExt tl = new InheritableThreadLocalExt();
}
static public class InheritableThreadLocalExt extends InheritableThreadLocal {
@Override
protected Object initialValue() {
return new Date().getTime();
}
@Override
protected Object childValue(Object parentValue) {
return parentValue + " 我在子线程加的~!";
}
}
static public class ThreadA extends Thread {
学习分享
在当下这个信息共享的时代,很多资源都可以在网络上找到,只取决于你愿不愿意找或是找的方法对不对了
很多朋友不是没有资料,大多都是有几十上百个G,但是杂乱无章,不知道怎么看从哪看起,甚至是看后就忘
如果大家觉得自己在网上找的资料非常杂乱、不成体系的话,我也分享一套给大家,比较系统,我平常自己也会经常研读。
2021最新上万页的大厂面试真题
七大模块学习资料:如NDK模块开发、Android框架体系架构...
只有系统,有方向的学习,才能在段时间内迅速提高自己的技术。
这份体系学习笔记,适应人群:
第一,学习知识比较碎片化,没有合理的学习路线与进阶方向。
第二,开发几年,不知道如何进阶更进一步,比较迷茫。
第三,到了合适的年纪,后续不知道该如何发展,转型管理,还是加强技术研究。如果你有需要,我这里恰好有为什么,不来领取!说不定能改变你现在的状态呢!
由于文章内容比较多,篇幅不允许,部分未展示内容以截图方式展示 。如有需要获取完整的资料文档的朋友点击我的GitHub免费获取。
|
免责声明:
1. 本站所有资源来自网络搜集或用户上传,仅作为参考不担保其准确性!
2. 本站内容仅供学习和交流使用,版权归原作者所有!© 查看更多
3. 如有内容侵害到您,请联系我们尽快删除,邮箱:kf@codeae.com
|
|
|
|
|
|
|
|
|


 QQ好友和群
QQ好友和群 QQ空间
QQ空间