这是老表12月的第4篇更文分享~记得关注我,坚持分享编程开发、数据分析、机器学习等学习笔记。作者:13妖、老表
跟老表一起学云服务器开发相关文章(如果是第一次阅读该系列文章, 强烈建议先学习下面文章):
先导篇:拥有有一台服务器后,我竟然这么酷?
替代项目:10行代码写一个简历页面!
和不安全访问 say goodbye,手把手教大家如何给域名申请免费 SSL 证书
Linux里的“宝塔”,真正的宝塔!详细教程
终于有了一个人人可以访问的网站了
如何用Python发送告警通知到钉钉?
一、软件准备
1.安装Python 环境
首先需要你的电脑安装好了Python环境,并且安装好了Python开发工具。如果你还没有安装,可以参考以下文章:如果仅用Python来处理数据、爬虫、数据分析或者自动化脚本、机器学习等,建议使用Python基础环境+jupyter即可,安装使用参考Windows/Mac 安装、使用Python环境+jupyter notebook
2.安装selenium库pip install selenium
3.下载谷歌浏览器驱动chromedriver,下载地址:http://npm.taobao.org/mirrors/chromedriver/需要选择对应的谷歌浏览器版本,(谷歌浏览器访问:chrome://settings/help,即可查看版本)
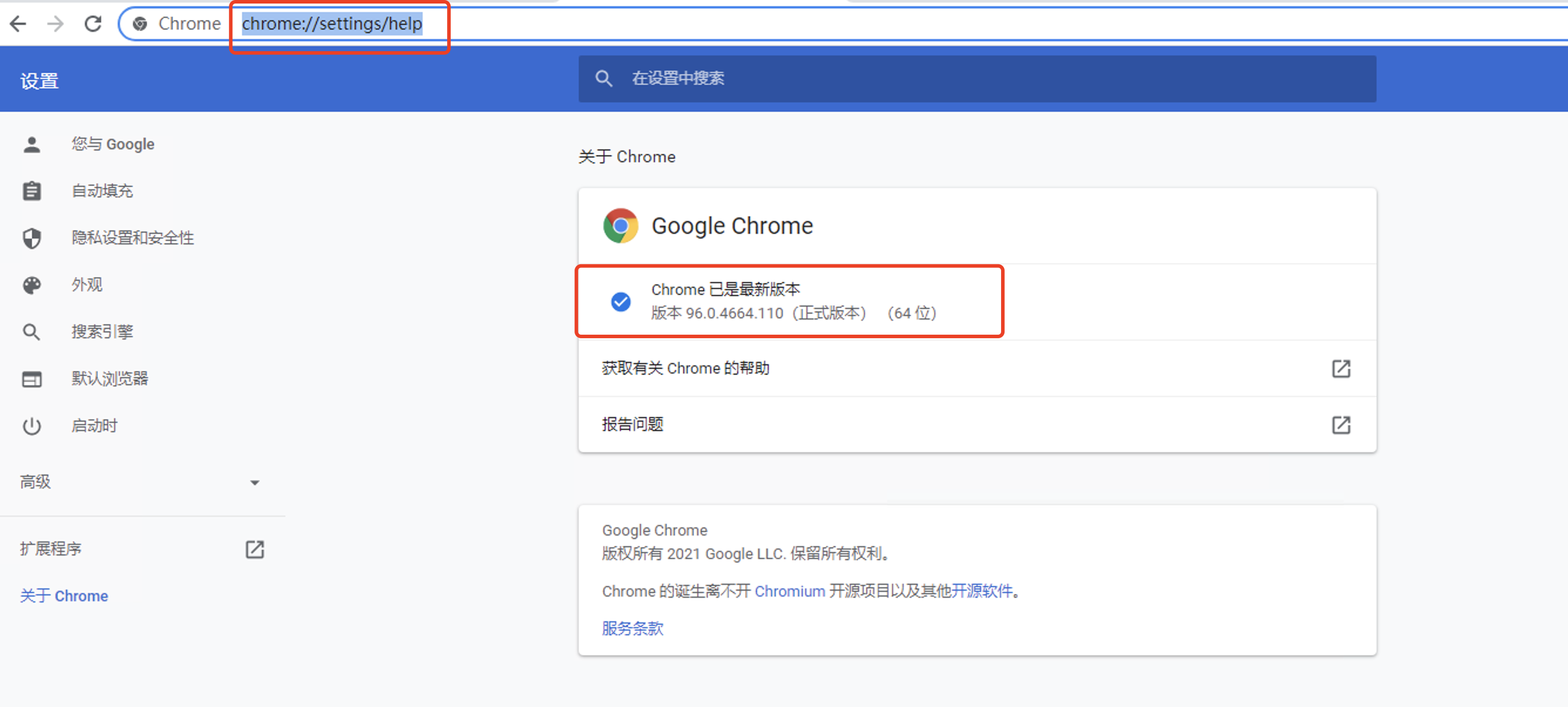
下载好后,随便发到一个路径下即可(简单点最好,记住路径)。
二、实现方法
2.1 使用 Selenium 工具自动化模拟浏览器,当前重点是了解对元素的定位
我们想定位一个元素,可以通过 id、name、class、tag、链接上的全部文本、链接上的部分文本、XPath 或者 CSS 进行定位,在 Selenium Webdriver 中也提供了这 8 种方法方便我们定位元素。
1)通过 id 定位:我们可以使用 find_element_by_id() 函数。比如我们想定位 id=loginName 的元素,就可以使用browser.find_element_by_id(“loginName”)。
2)通过 name 定位:我们可以使用 find_element_by_name() 函数,比如我们想要对 name=key_word 的元素进行定位,就可以使用 browser.find_element_by_name(“key_word”)。
3)通过 class 定位:可以使用 find_element_by_class_name() 函数。
4)通过 tag 定位:使用 find_element_by_tag_name() 函数。
5)通过 link 上的完整文本定位:使用 find_element_by_link_text() 函数。
6)通过 link 上的部分文本定位:使用 find_element_by_partial_link_text() 函数。有时候超链接上的文本很长,我们通过查找部分文本内容就可以定位。
7)通过 XPath 定位:使用 find_element_by_xpath() 函数。使用 XPath 定位的通用性比较好,因为当 id、name、class 为多个,或者元素没有这些属性值的时候,XPath 定位可以帮我们完成任务。
8)通过 CSS 定位:使用 find_element_by_css_selector() 函数。CSS 定位也是常用的定位方法,相比于 XPath 来说更简洁。
2.2 对元素进行的操作包括
1)清空输入框的内容:使用 clear() 函数;2)在输入框中输入内容:使用 send_keys(content) 函数传入要输入的文本;3)点击按钮:使用 click() 函数,如果元素是个按钮或者链接的时候,可以点击操作;4)提交表单:使用 submit() 函数,元素对象为一个表单的时候,可以提交表单;
2.3 注意
由于selenium打开的chrome是原始设置的,所以访问微博首页时一定会弹出来是否提示消息的弹窗,导致不能定位到输入框。可使用如下方法关闭弹窗:prefs = {"profile.default_content_setting_values.notifications": 2}
2.4 如何定位元素
点击需要定位的元素,然后右键选择检查,可以调出谷歌开发者工具。
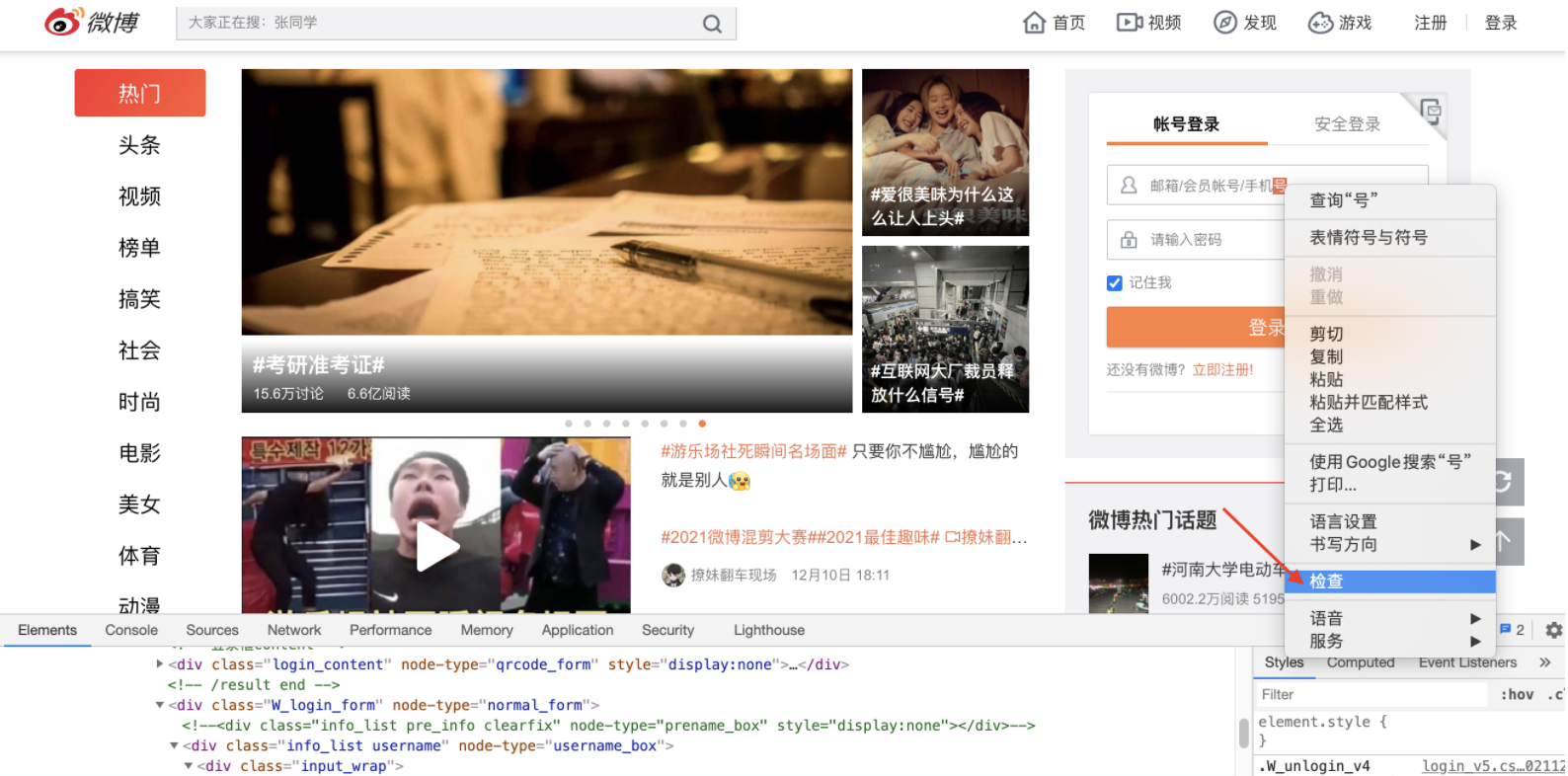
获取xpath 路径,点击谷歌开发者工具左上角的小键头(选择元素),选择自己要查看的地方的,开发者工具就会自动定位到对应元素的源码位置,选中对应源码,然后右键,选择Copy-> Copy XPath即可获取到xpath 路径。
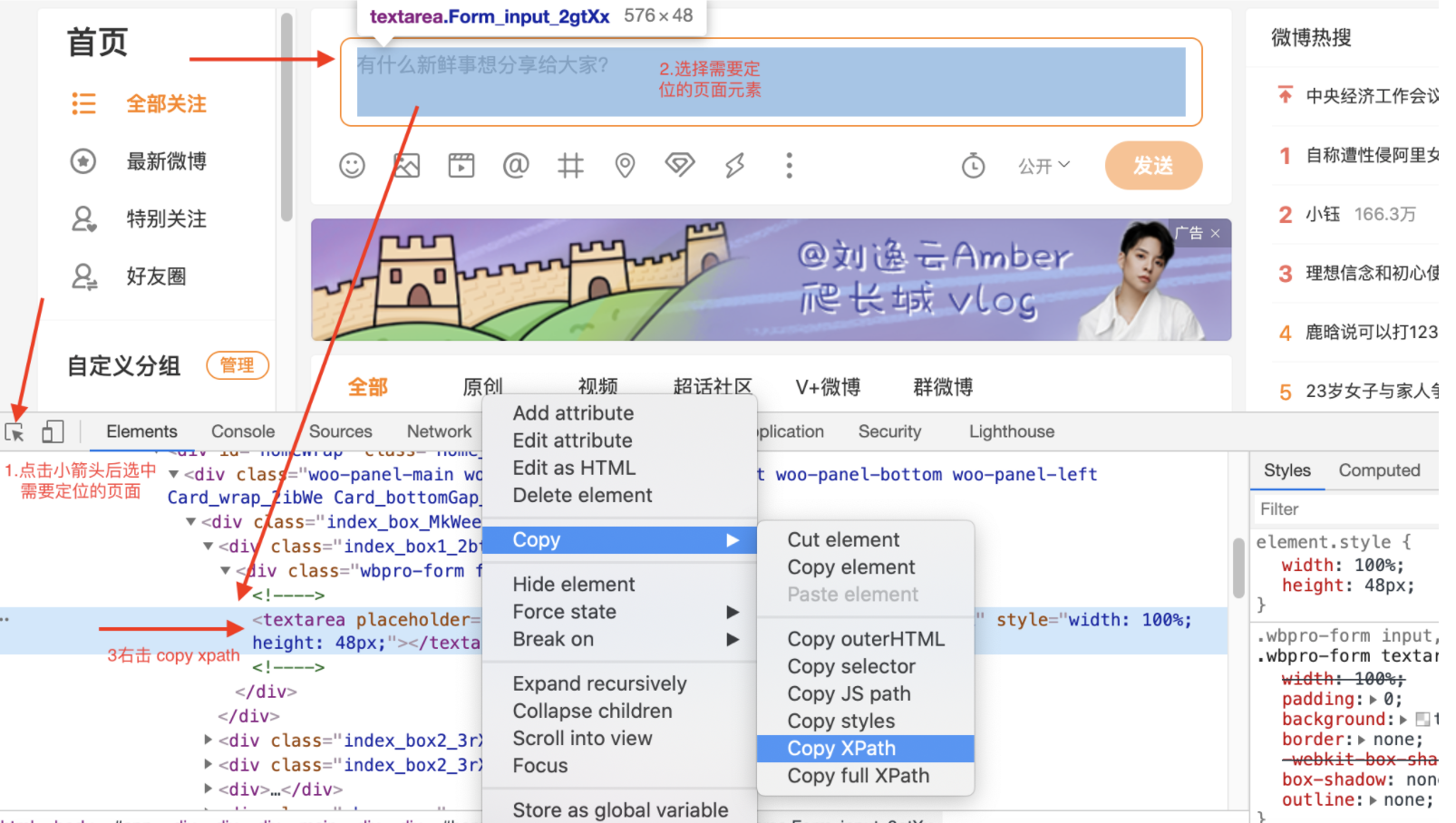 另外: 可以下载 XPath Helper插件,安装后 在网页上选取想要提取的元素, 点击右键 选中 检查 然后 开发者工具自动打开 你可以看到 HTML代码 ,选中然后再次点击右键,选中copy 里的 copy to xpath这样就得到了xpath的值了。 另外: 可以下载 XPath Helper插件,安装后 在网页上选取想要提取的元素, 点击右键 选中 检查 然后 开发者工具自动打开 你可以看到 HTML代码 ,选中然后再次点击右键,选中copy 里的 copy to xpath这样就得到了xpath的值了。
三、完整代码
实现思路: 其实和平时我们正常操作一样,只不过这里,全程由selenium来实现,模拟点击和输入,所以整个过程为:打开登录页面->输入账号密码->点击登录按钮->在发微博框输入发送内容->点击发送按钮->关闭浏览器(自选)。
3.1 目前自动输入账号可能会弹出登录保护需扫二维码验证
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
'''
自动发布微博
content:发送内容
username:微博账号
password:微博密码
'''
def post_weibo(content, username, password):
# 加载谷歌浏览器驱动
path = r'C:/MyEnv/chromedriver.exe ' # 指定驱动存放目录
ser = Service(path)
chrome_options = webdriver.ChromeOptions()
# 把允许提示这个弹窗关闭
prefs = {"profile.default_content_setting_values.notifications": 2}
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(service=ser, options=chrome_options)
driver.maximize_window() # 设置页面最大化,避免元素被隐藏
print('# get打开微博主页')
url = 'http://weibo.com/login.php'
driver.get(url) # get打开微博主页
time.sleep(5) # 页面加载完全
print('找到用户名 密码输入框')
input_account = driver.find_element_by_id('loginname') # 找到用户名输入框
input_psw = driver.find_element_by_css_selector('input[type="password"]') # 找到密码输入框
# 输入用户名和密码
input_account.send_keys(username)
input_psw.send_keys(password)
print('# 找到登录按钮 //div[@node-type="normal_form"]//div[@class="info_list login_btn"]/a')
bt_logoin = driver.find_element_by_xpath('//div[@node-type="normal_form"]//div[@class="info_list login_btn"]/a') # 找到登录按钮
bt_logoin.click() # 点击登录
# 等待页面加载完毕 #有的可能需要登录保护,需扫码确认下
time.sleep(40)
# 登录后 默认到首页,有微博发送框
print('# 找到文本输入框 输入内容 //*[@id="homeWrap"]/div[1]/div/div[1]/div/textarea')
weibo_content = driver.find_element_by_xpath('//*[@id="homeWrap"]/div[1]/div/div[1]/div/textarea')
weibo_content.send_keys(content)
print('# 点击发送按钮 //*[@id="homeWrap"]/div[1]/div/div[4]/div/button')
bt_push = driver.find_element_by_xpath('//*[@id="homeWrap"]/div[1]/div/div[4]/div/button')
bt_push.click() # 点击发布
time.sleep(15)
driver.close() # 关闭浏览器
if __name__ == '__main__':
username = '微博用户名'
password = "微博密码"
# 自动发微博
content = '每天进步一点'
post_weibo(content, username, password)
通过cookie进行登录可跳过扫码登录,cookie过期后重新获取下cookie就可以了。
导入第三方包from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
import requests
import json
获取cookie到本地
这里主要利用了selenium的get_cookies函数获取cookies。# 获取cookies 到本地
def get_cookies(driver):
driver.get('https://weibo.com/login.php')
time.sleep(20) # 留时间进行扫码
Cookies = driver.get_cookies() # 获取list的cookies
jsCookies = json.dumps(Cookies) # 转换成字符串保存
with open('cookies.txt', 'w') as f:
f.write(jsCookies)
print('cookies已重新写入!')
# 读取本地的cookies
def read_cookies():
with open('cookies.txt', 'r', encoding='utf8') as f:
Cookies = json.loads(f.read())
cookies = []
for cookie in Cookies:
cookie_dict = {
'domain': '.weibo.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
'expires': '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
cookies.append(cookie_dict)
return cookies
利用cookie登录微博并发送文字 完整代码
# 初始化浏览器 打开微博登录页面
def init_browser():
path = r'C:/MyEnv/chromedriver.exe ' # 指定驱动存放目录
ser = Service(path)
chrome_options = webdriver.ChromeOptions()
# 把允许提示这个弹窗关闭
prefs = {"profile.default_content_setting_values.notifications": 2}
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(service=ser, options=chrome_options)
driver.maximize_window()
driver.get('https://weibo.com/login.php')
return driver
# 读取cookies 登录微博
def login_weibo(driver):
cookies = read_cookies()
for cookie in cookies:
driver.add_cookie(cookie)
time.sleep(3)
driver.refresh() # 刷新网页
# 发布微博
def post_weibo(content, driver):
time.sleep(5)
weibo_content = driver.find_element_by_xpath('//*[ @id ="homeWrap"]/div[1]/div/div[1]/div/textarea')
weibo_content.send_keys(content)
bt_push = driver.find_element_by_xpath('//*[@id="homeWrap"]/div[1]/div/div[4]/div/button')
bt_push.click() # 点击发布
time.sleep(5)
driver.close() # 关闭浏览器
if __name__ == '__main__':
# cookie登录微博
driver = init_browser()
login_weibo(driver)
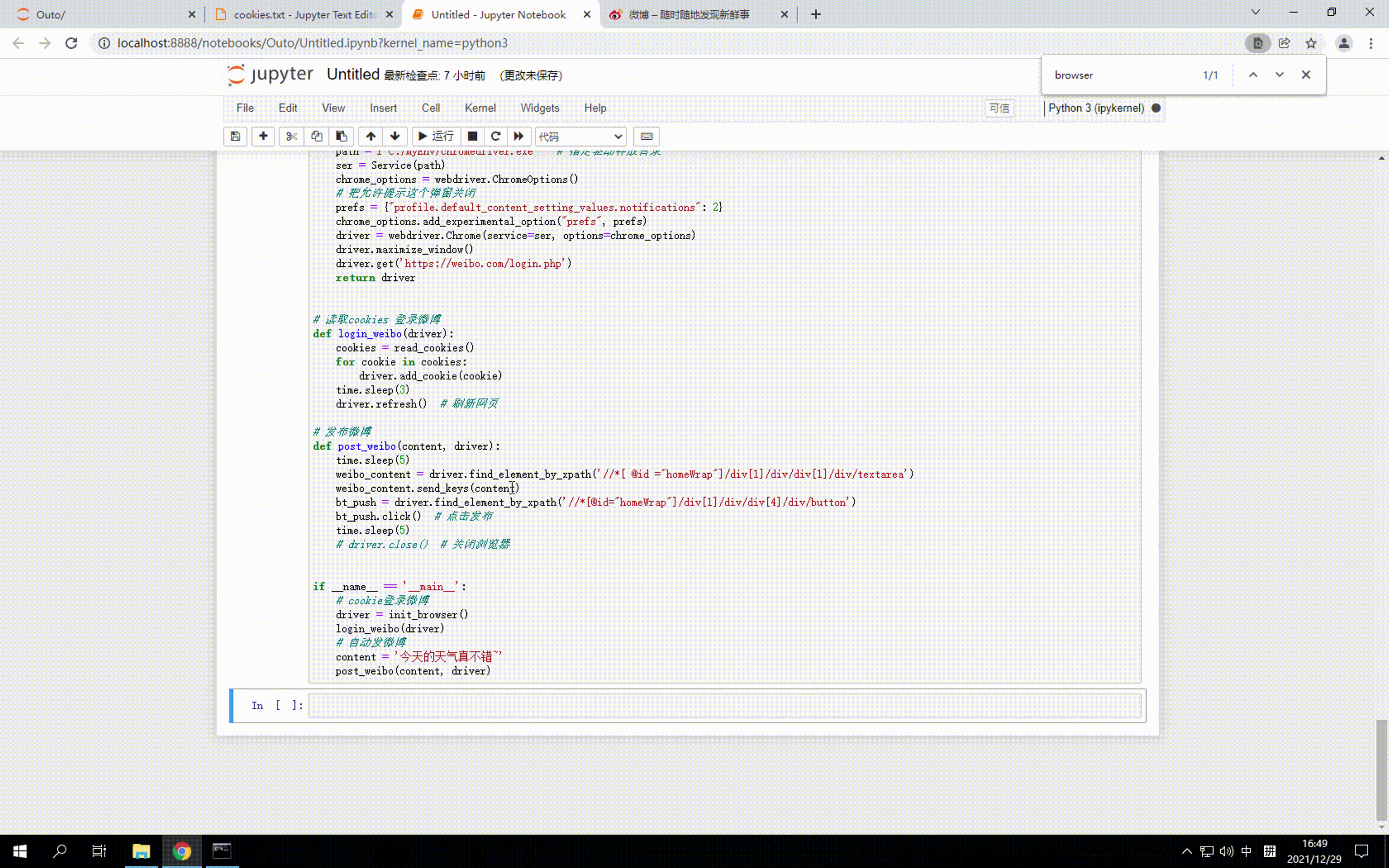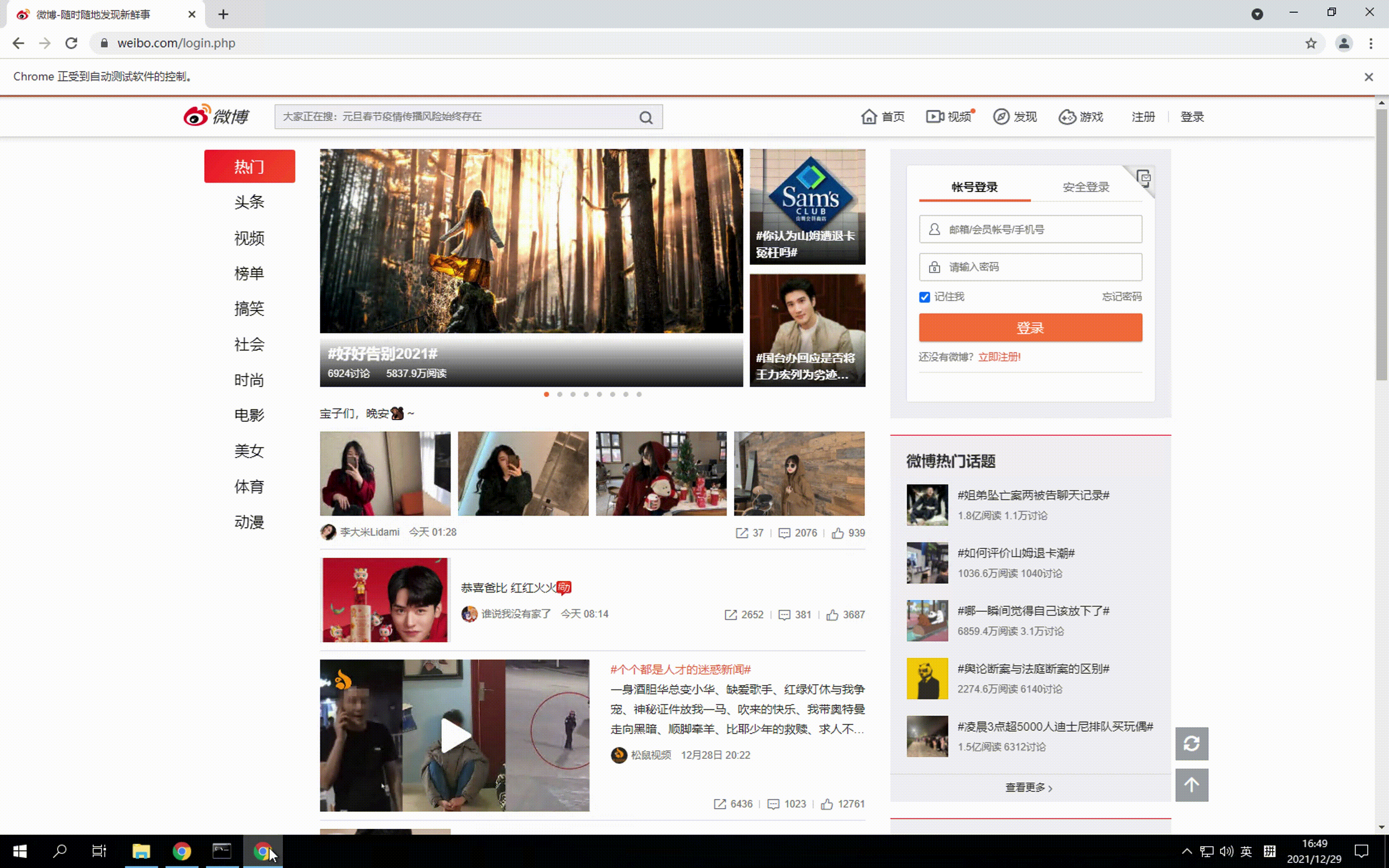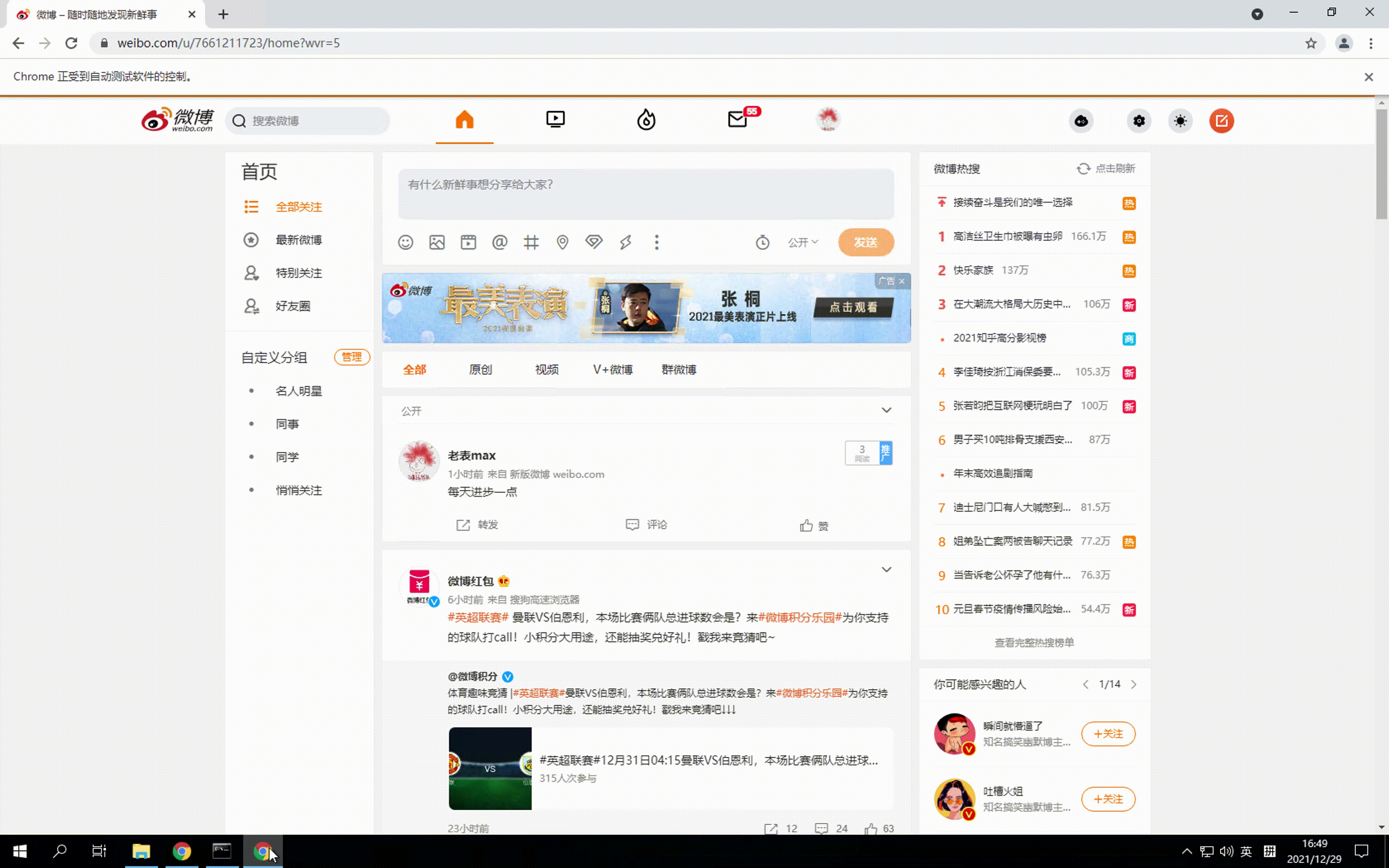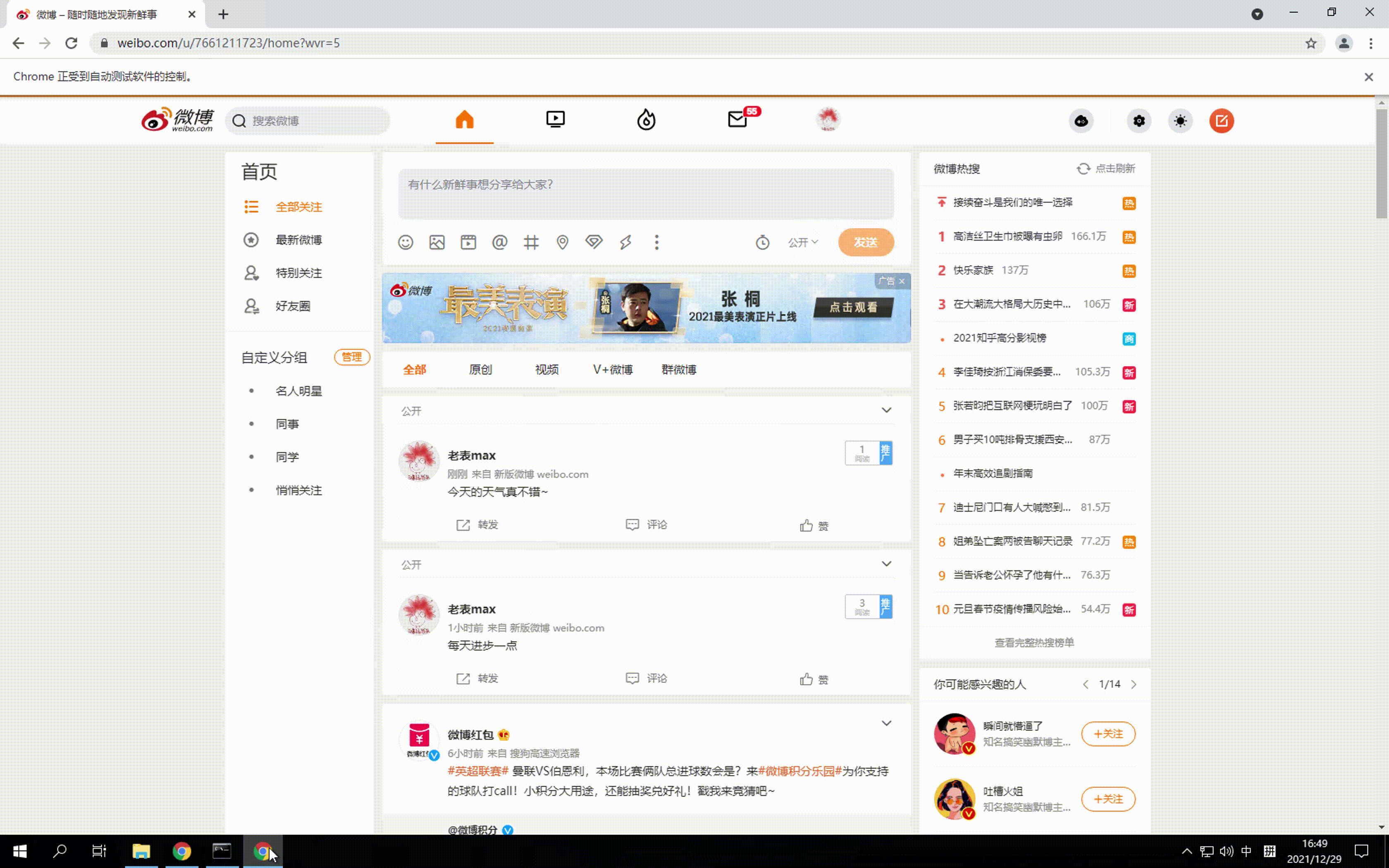
# 自动发微博
content = '今天的天气真不错~'
post_weibo(content, driver)
拓展:检测cookies有效性
检测方法:利用本地cookies向微博发送get请求,如果返回的页面源码中包含自己的微博昵称,就说明cookies还有效,否则无效。
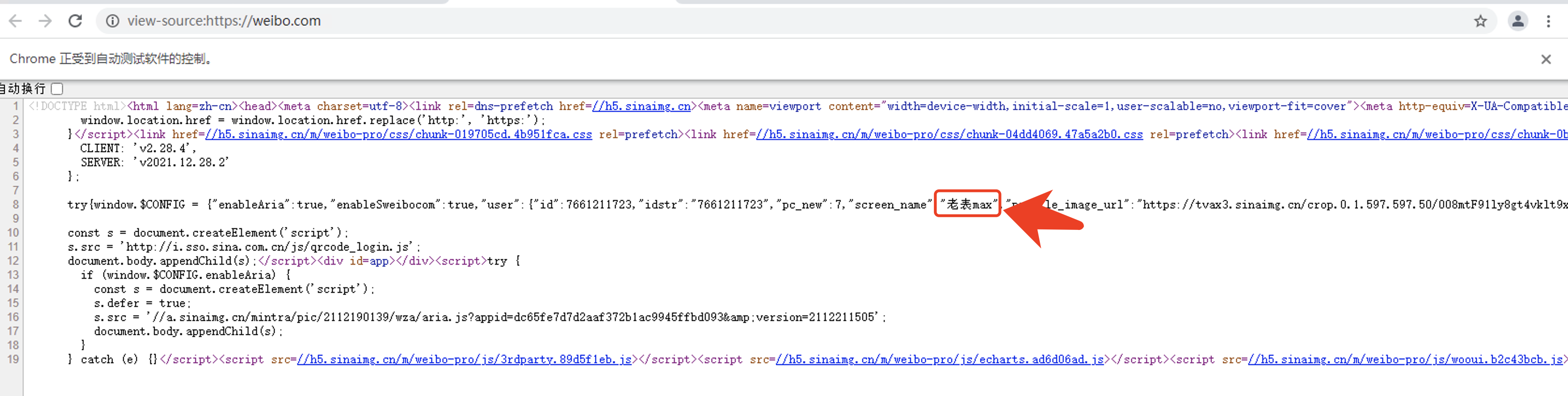 # 检测cookies的有效性
def check_cookies():
# 读取本地cookies
cookies = read_cookies()
s = requests.Session()
for cookie in cookies:
s.cookies.set(cookie['name'], cookie['value'])
response = s.get("https://weibo.com")
html_t = response.text
# 检测页面是否包含我的微博用户名
if '老表max' in html_t:
return True
else:
return False
拓展:定时每日自动发送
可以参考上一篇文章:如何用Python发送告警通知到钉钉?包括如何设置守护进程,在上一篇文章中也有介绍。from apscheduler.schedulers.blocking import BlockingSchedulera
'''
每天早上9:00 发送一条微博
'''
def every_day_nine():
# cookie登录微博
driver = init_browser()
login_weibo(driver)
req = requests.get('https://hitokoto.open.beeapi.cn/random')
get_sentence = req.json()
content = f'【每日一言】{get_sentence["data"]} 来自:一言api'
# 自动发微博
post_weibo(content, driver)
# 选择BlockingScheduler调度器
sched = BlockingScheduler(timezone='Asia/Shanghai')
# job_every_nine 每天早上9点运行一次 日常发送
sched.add_job(every_day_nine, 'cron', hour=9)
# 启动定时任务
sched.start()
下期预告
凡是自动化的东西,都可以发抖服务器上持续的去跑,当然,本地电脑也可以进行学习使用。下一期,感觉有太多东西需要更新了,慢慢来吧,提前祝大家元旦快乐~2022,我准备好了!
好的,那么下期见,我是爱猫爱技术,更爱思思的老表⁽⁽ଘ( ˙꒳˙ )ଓ⁾⁾
| 

 QQ好友和群
QQ好友和群 QQ空间
QQ空间