
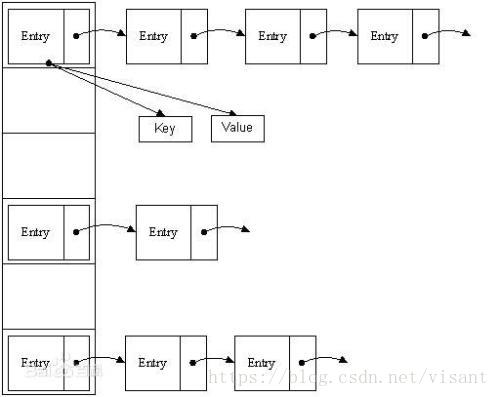
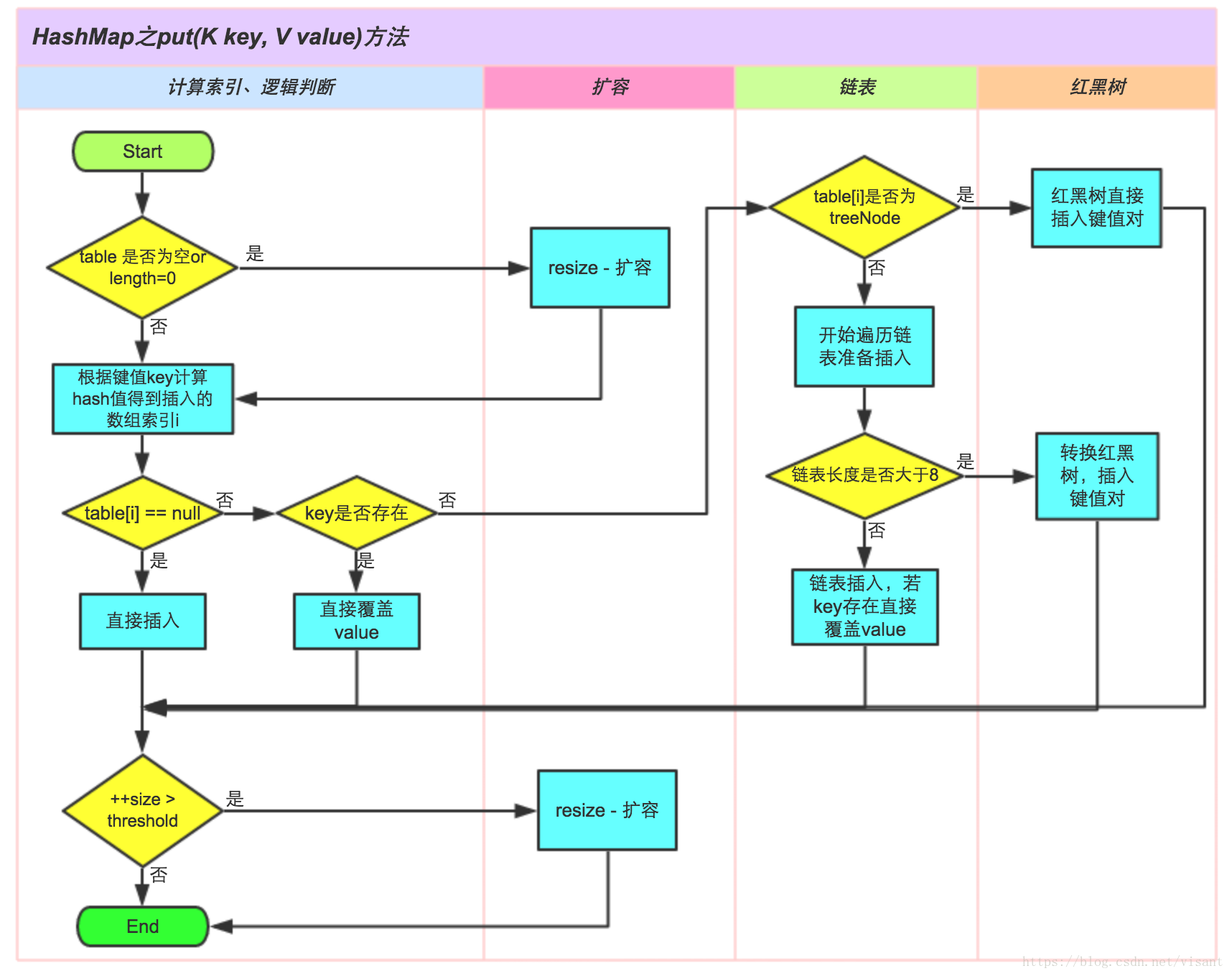
[Java] HashMap原理的深入理解
![]() 编程语言
发布于:2021-08-17 12:56
|
阅读数:518
|
评论:0
编程语言
发布于:2021-08-17 12:56
|
阅读数:518
|
评论:0
免责声明:
1. 本站所有资源来自网络搜集或用户上传,仅作为参考不担保其准确性! 2. 本站内容仅供学习和交流使用,版权归原作者所有!© 查看更多 3. 如有内容侵害到您,请联系我们尽快删除,邮箱:kf@codeae.com | ||

 QQ好友和群
QQ好友和群 QQ空间
QQ空间
相关帖子
-
深入解析Linux下的磁盘缓存机制与SSD的写入放大问题
湛蓝之海 阅读 343 0 赞
-
深入解析Linux系统中的SELinux访问控制功能
湛蓝之海 阅读 350 0 赞
-
自上而下的理解网络(6)——终篇!ARP与Ethernet Ⅱ
飞奔的炮台 阅读 355 0 赞
-
深入分析Z-Order
小蚂蚁 阅读 751 0 赞
-
Android下的Drawable使用
浅沫记忆 阅读 648 0 赞
-
以下文体中,有一种不是公文,即( )。
三叶草 阅读 186 0 赞
-
图文并茂!推荐算法架构——粗排
浅沫记忆 阅读 406 0 赞
-
Android Proguard混淆对抗之我见
飞奔的炮台 阅读 509 0 赞
-
Java京东面试题之为什么HashMap线程不安全
小蚂蚁 阅读 458 0 赞
-
MySQL让人又爱又恨的多表查询
浅沫记忆 阅读 549 0 赞

发布文档 1502
热门推荐
-
Redis实现延迟任务的三种方法详解
CodeAE 2025-04-12
-
关于GBK与UTF-8互转乱码问题解读
CodeAE 2025-03-09
-
EasyBCD系统引导修复工具 V2.4.0 中文版
CodeAE 2024-12-14
-
图吧工具箱2024.9绿色版
CodeAE 2024-12-12
-
Win10右键管理提示“该文件没有与之关联的程序来执行此操作”怎么办
CodeAE 2024-12-08
-
如何白嫖一张永不过期的SSL证书
CodeAE 2024-11-17
-
自己动手写一个挪车通知工具
CodeAE 2024-11-10
-
如何利用html+js写一个大小写字母互转工具
CodeAE 2024-10-20
-
Discuz教程-帖子里有多个MP4媒体,默认只播放一个
CodeAE 2024-10-13
-
Discuz教程-禁止复制及使用f12开发者模式
CodeAE 2024-10-13
-
C/C++实现植物大战僵尸
CodeAE 2024-10-05
-
B站视频下载工具 Bilidown 1.2.0
CodeAE 2024-10-03
-
2024显卡天梯图一览表
CodeAE 2024-09-01
-
win10怎么查看电脑配置显卡 电脑查看显卡配置方法
CodeAE 2024-08-25
-
Word文档中的doc和docx格式有什么区别?
CodeAE 2024-07-21
-
禁止win10更新的方法
CodeAE 2024-06-02
-
查看Window激活状态的方法
CodeAE 2024-05-26
-
利用宝塔面板实现夸克网盘自动签到获取永久容量
CodeAE 2024-05-01